CSP 2019 入门组第一轮 计数排序¶
背景知识:¶
计数排序,假设n个输入元素中的每一个都是在 0 到 k 区间内的一个整数,其中 k 为某个整数。计数排序的基本思想是,对每一个输入元素 x ,确定小于 x 的元素个数。利用这一信息,就可以直接把 x 放到它在输出数组中的位置上了。
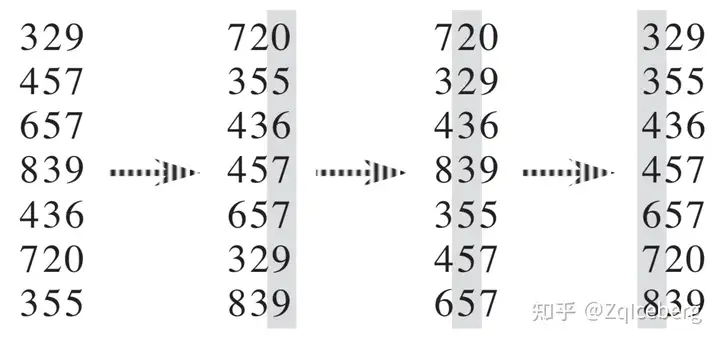
基数排序(radix sort)是先按最低有效位进行排序来解决卡片排序问题的,然后算法将所有卡片合并成一叠,其中 0 号容器中的卡片都在 1 号容器中的卡片之前,而1号容器中的卡片又在 2 号容器中的卡片前面,依此类推。
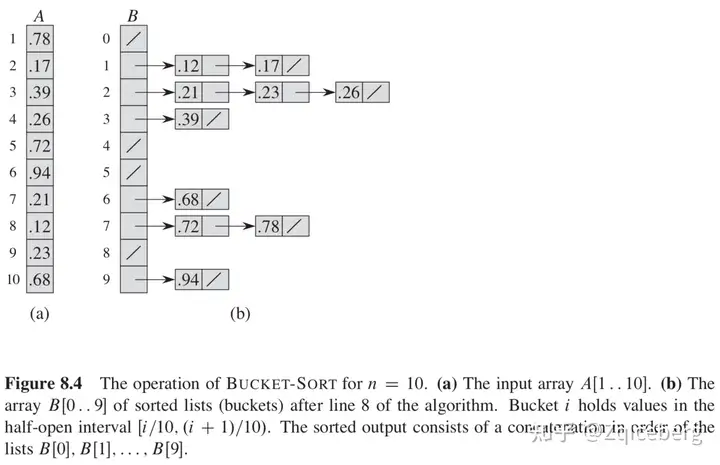
桶排序(bucket sort),将[0, 1)区间划分为n个相同大小的子区间,或称之为桶。然后,将 n 个输入数分别放到各个桶中。因为输入数据是均匀、独立分布在[0, 1)区间上,所以一般不会出现很多数落在同一个桶中的情况。为了得到输出结果,我们先对每个桶的数进行排序,然后遍历每个桶,按照次序把各个桶中的元素列出来即可。
题目:¶

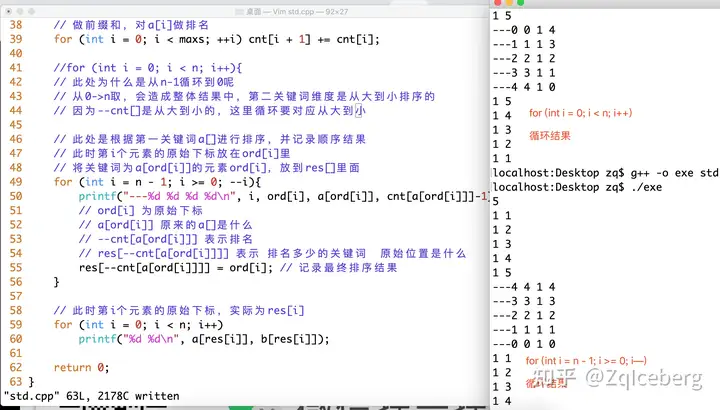
基于计数排序,程序实际实现了近似于基数排序的算法,依次以低位到高位的每一位数为关键词,进行计数排序,前一次的排序结果是下一次的初始序列。先根据第二关键词b[ ]进行计数排序,再根据第一关键词a[ ]进行计数排序。
#include <cstdio>
#include <cstring>
using namespace std;
const int maxn = 10000000;
const int maxs = 10000;
int n;
unsigned a[maxn], b[maxn],res[maxn], ord[maxn];
unsigned cnt[maxs + 1];
int main() {
scanf("%d", &n);
for (int i = 0; i < n; ++i) scanf("%d%d", &a[i], &b[i]);
// 利用 cnt 数组统计数量
// 根据第二关键词b[]进行计数排序,对b[i]进行统计
memset(cnt, 0, sizeof(cnt));
for (int i = 0; i < n; ++i) cnt[b[i]]++;
// 做前缀和,本质上就是做b[i]的排名了
for (int i = 0; i < maxs; ++i) cnt[i + 1] += cnt[i];
// 记录初步排序结果
// 此处是根据第二关键词b[]进行计数排序,并记录结果
// 此时的cnt[key]用于表示关键词为key的元素在结果数组中的位置
// 将关键词为b[i]的元素i放到结束数组ord[]中
// 表示排名 --cnt[b[i]] 的元素 是原始第i个数
// ord[--cnt[b[i]]]=i
for (int i = 0; i < n; ++i) ord[--cnt[b[i]]] = i;
// 利用 cnt 数组统计数量
// 对第一关键词a[]进行计数排序
memset(cnt, 0, sizeof(cnt));
for (int i = 0; i < n; ++i) cnt[a[i]]++;
// 做前缀和,对a[i]做排名
for (int i = 0; i < maxs; ++i) cnt[i + 1] += cnt[i];
//for (int i = 0; i < n; i++){
// 此处为什么是从n-1循环到0呢
// 如果从0->n取,会造成整体结果中,第二关键词维度是从大到小排序的
// 因为前面,i:0->n-1, 对应 --cnt[]是从大到小的
// 排名较小的,对应的是 n-1 这头。此处,后面给出了样例分析
// 此处是根据第一关键词a[]进行排序,并记录顺序结果
// 此时第i个元素的原始下标放在ord[i]里
// 将关键词为a[ord[i]]的元素ord[i],放到res[]里面
for (int i = n - 1; i >= 0; --i){
printf("---%d %d %d %d\n", i, ord[i], a[ord[i]], cnt[a[ord[i]]]-1);
// ord[i] 为原始下标
// a[ord[i]] 原来的a[]是什么
// --cnt[a[ord[i]]] 表示排名
// res[--cnt[a[ord[i]]]] 表示 排名多少的关键词 原始位置是什么
res[--cnt[a[ord[i]]]] = ord[i]; // 记录最终排序结果
}
// 此时第i个元素的原始下标,实际为res[i]
for (int i = 0; i < n; i++)
printf("%d %d\n", a[res[i]], b[res[i]]);
return 0;
}